Twitter snowflake ID 算法之 golang 实现
是什么?
snowflake ID 算法是 twitter 使用的唯一 ID 生成算法,为了满足 Twitter 每秒上万条消息的请求,使每条消息有唯一、有一定顺序的 ID ,且支持分布式生成。
主要解决了高并发时 ID 生成不重复的问题
结构
snowflake ID 的结构是一个 64 bit 的 int 型数据。
如图所示 :
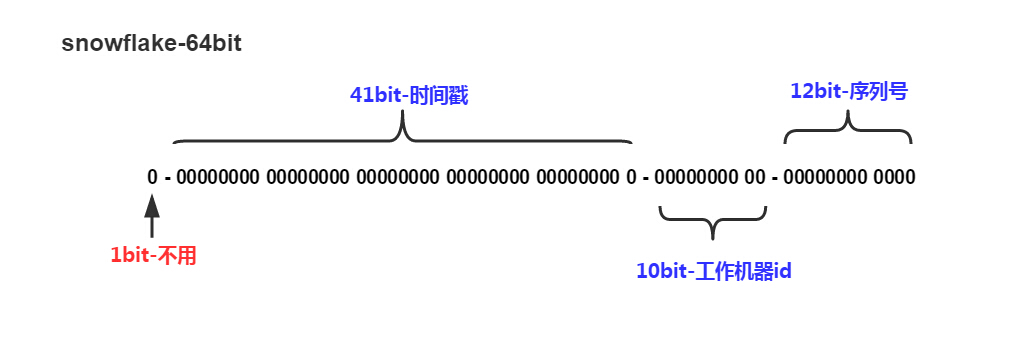
1 bit:不使用,可以是 1 或 0
41 bit:记录时间戳 (当前时间戳减去用户设置的初始时间,毫秒表示),可记录最多 69 年的时间戳数据
10 bit:用来记录分布式节点 ID,一般每台机器一个唯一 ID,也可以多进程每个进程一个唯一 ID,最大可部署 1024 个节点
12 bit:序列号,用来记录不同 ID 同一毫秒时的序列号,最多可生成 4096 个序列号
时间戳、节点 ID 和序列号的位数可以根据业务自由浮动调整
唯一 ID 原理
假设在一个节点 (机器) 上,节点 ID 唯一,并发时有多个线程去生成 ID。
满足以上条件时,如果多个进程在同一毫秒内生成 ID,那么序列号步进 (加一),这里要保证序列号的操作并发安全,使同一毫秒内生成的 ID 拥有不同序列号。如果序列号达到上限,则等待这一毫秒结束,在新的毫秒继续步进。
这样保证了:
所有生成的 ID 按时间趋势递增
整个分布式系统内不会产生重复 ID
用 go 实现的思路
why go ?
go 有封装好的协程 goroutine,可以很好的处理并发,可以加锁保证数据的同步安全,有很好的性能。当然其它语言如 Java、Scala 也是完全可以的。
思路
1、确定唯一的节点 ID
2、设置一个初始时间戳 (毫秒表示)
3、处理并发时序列号步进和并发安全问题
4、组装各个 bits ,生成最终的 64 bit ID
编码实现
首先我们要引入基础的模块
import (
"fmt" // 测试、打印
"time" // 获取时间
"errors" // 生成错误
"sync" // 使用互斥锁
)
基础常量定义
这里求最大值使用了位运算,-1 的二进制表示为 1 的补码,感兴趣的同学可以自己算算试试 -1 ^ (-1 « nodeBits) 这里是不是等于 1023
const (
nodeBits uint8 = 10 // 节点 ID 的位数
stepBits uint8 = 12 // 序列号的位数
nodeMax int64 = -1 ^ (-1 << nodeBits) // 节点 ID 的最大值,用于检测溢出
stepMax int64 = -1 ^ (-1 << stepBits) // 序列号的最大值,用于检测溢出
timeShift uint8 = nodeBits + stepBits // 时间戳向左的偏移量
nodeShift uint8 = stepBits // 节点 ID 向左的偏移量
)
设置初始时间的时间戳 (毫秒表示),我这里使用 twitter 设置的一个时间,这个可以随意设置 ,比现在的时间靠前即可。
var Epoch int64 = 1288834974657 // timestamp 2006-03-21:20:50:14 GMT
ID 结构和 Node 结构的实现 这里我们申明一个 int64 的 ID 类型 (这样可以为此类型定义方法,比直接使用 int64 变量更灵活)
type ID int64
Node 结构用来存储一个节点 (机器) 上的基础数据
type Node struct {
mu sync.Mutex // 添加互斥锁,保证并发安全
timestamp int64 // 时间戳部分
node int64 // 节点 ID 部分
step int64 // 序列号 ID 部分
}
获取 Node 类型实例的函数,用于获得当前节点的 Node 实例
func NewNode(node int64) (*Node, error) {
// 如果超出节点的最大范围,产生一个 error
if node < 0 || node > nodeMax {
return nil, errors.New("Node number must be between 0 and 1023")
}
// 生成并返回节点实例的指针
return &Node{
timestamp: 0,
node: node,
step: 0,
}, nil
}
最后一步,生成 ID 的方法
func (n *Node) Generate() ID {
n.mu.Lock() // 保证并发安全, 加锁
defer n.mu.Unlock() // 方法运行完毕后解锁
// 获取当前时间的时间戳 (毫秒数显示)
now := time.Now().UnixNano() / 1e6
if n.timestamp == now {
// step 步进 1
n.step ++
// 当前 step 用完
if n.step > stepMax {
// 等待本毫秒结束
for now <= n.timestamp {
now = time.Now().UnixNano() / 1e6
}
}
} else {
// 本毫秒内 step 用完
n.step = 0
}
n.timestamp = now
// 移位运算,生产最终 ID
result := ID((now - Epoch) << timeShift | (n.node << nodeShift) | (n.step))
return result
}
测试
我们使用循环去开启多个 goroutine 去并发生成 ID,然后使用 map 以 ID 作为键存储,来判断是否生成了唯一的 ID
main 函数代码
func main() {
// 测试脚本
// 生成节点实例
node, err := NewNode(1)
if err != nil {
fmt.Println(err)
return
}
ch := make(chan ID)
count := 10000
// 并发 count 个 goroutine 进行 snowflake ID 生成
for i := 0; i < count; i++ {
go func() {
id := node.Generate()
ch <- id
}()
}
defer close(ch)
m := make(map[ID]int)
for i := 0; i < count; i++ {
id := <- ch
// 如果 map 中存在为 id 的 key, 说明生成的 snowflake ID 有重复
_, ok := m[id]
if ok {
fmt.Printf("ID is not unique!\n")
return
}
// 将 id 作为 key 存入 map
m[id] = i
}
// 成功生成 snowflake ID
fmt.Println("All ", count, " snowflake ID generate successed!\n")
}
完整的程序实例 :点我查看
上线使用
你可以用 go 的 net/http 包处理并发请求,生成 ID 并且返回 http 响应结果。
Just do it
参考文章
上一篇 : Laravel 创建自己的 Facade
下一篇 : 写一个“特殊”的查询构造器 - (前言)